Log时序数据异常检测
!!以下内容均摘自阿里云SLS机器学习介绍,写得实在太好了。!!
1 背景
数量多:以阿里云神农系统为例,一台机器有3500多个时序数据,以5秒作为采样周期1000台集群计算,每秒钟会产生70W个点。
生成时序数据是为了对业务进行监控和报警,但这块目前非常依赖与人的经验,我们来看几个典型的问题:
1.1 异常示例
问题1:业务/交易走势异常发现
业务系统调用量异常:以云服务提供的API为例,因各种原因会有一个短暂的Burst和下降。对于重要接口可以在监控系统上发现,但当我们面向几百个接口的监控时也会力不从心。
例如下图的监控中,在2分钟时间内流量大小下跌30%以上,在2分钟内后又迅速恢复:
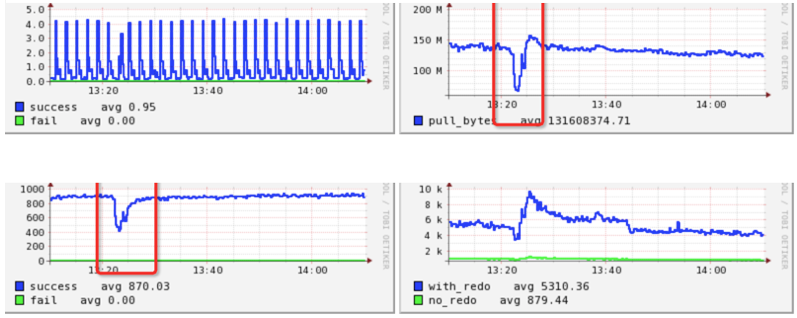
应对这种情况有几种典型做法:
- 同环比,例如和上一周、上一天同一时刻比较,如果下降或上升一定大小(例如30%),则产生报警
- 假设系统是平滑的,与上一时刻比较,如果有比较大差距则认为是巨大变化,产生报警【这是我们目前异常监测能做到的】
- 通过统计建模估算大致走势,如果违背则认为是异常报警
这些方法有比较强的假设,并对数据的精度有较为严格的要求,在生产中容易产生误报。
问题2:异常点发现
延时的毛刺:在对读写敏感的场景中,经常会有IO毛刺问题困扰,这些毛刺往往被平均难以通过肉眼或P99等监控方法发现。
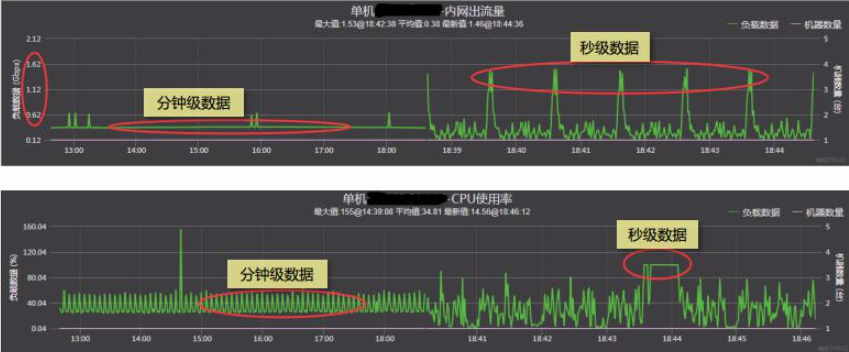
问题3:延时是否是正常
与Pangu团队交流时发现,Latency告警是一个很依赖经验的问题,无法使用例如业务量等传统时序建模手段。主要有几大原因:
- Latency 在QPS等请求上升时,一般都是趋于稳定的。
- Latency 下降并不能说系统出了问题,有可能当前没有访问。
- Latency 上升可能和系统的压力、请求,机器负载相关,上升30%可能是请求多了排队引擎,并不是软件或系统Hang。
因此Latency是否正常判断,不能以单一要素维度去建模,要考虑到相关因素。
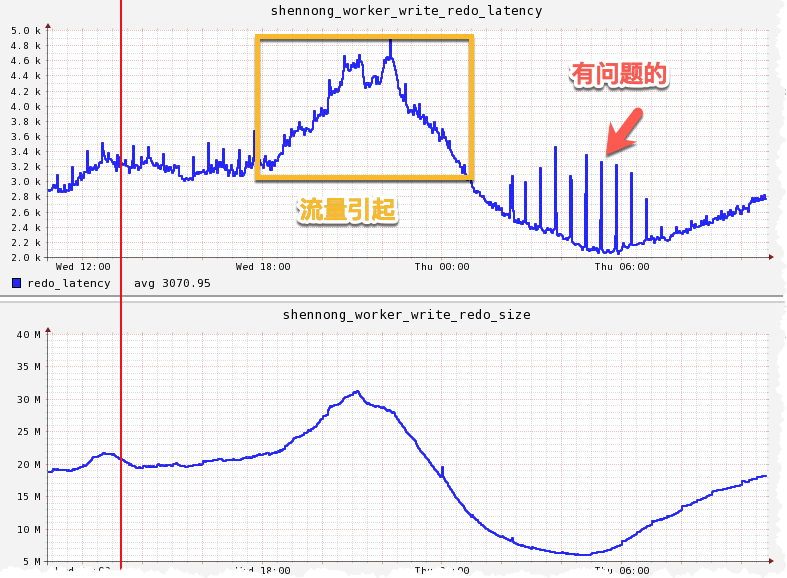
问题4:在大量实例中发现问题
在生产环境中异常检测需要从几千个、几十万个实例中去发现不一样的实例。传统的人肉判断方法会显得力不从心。
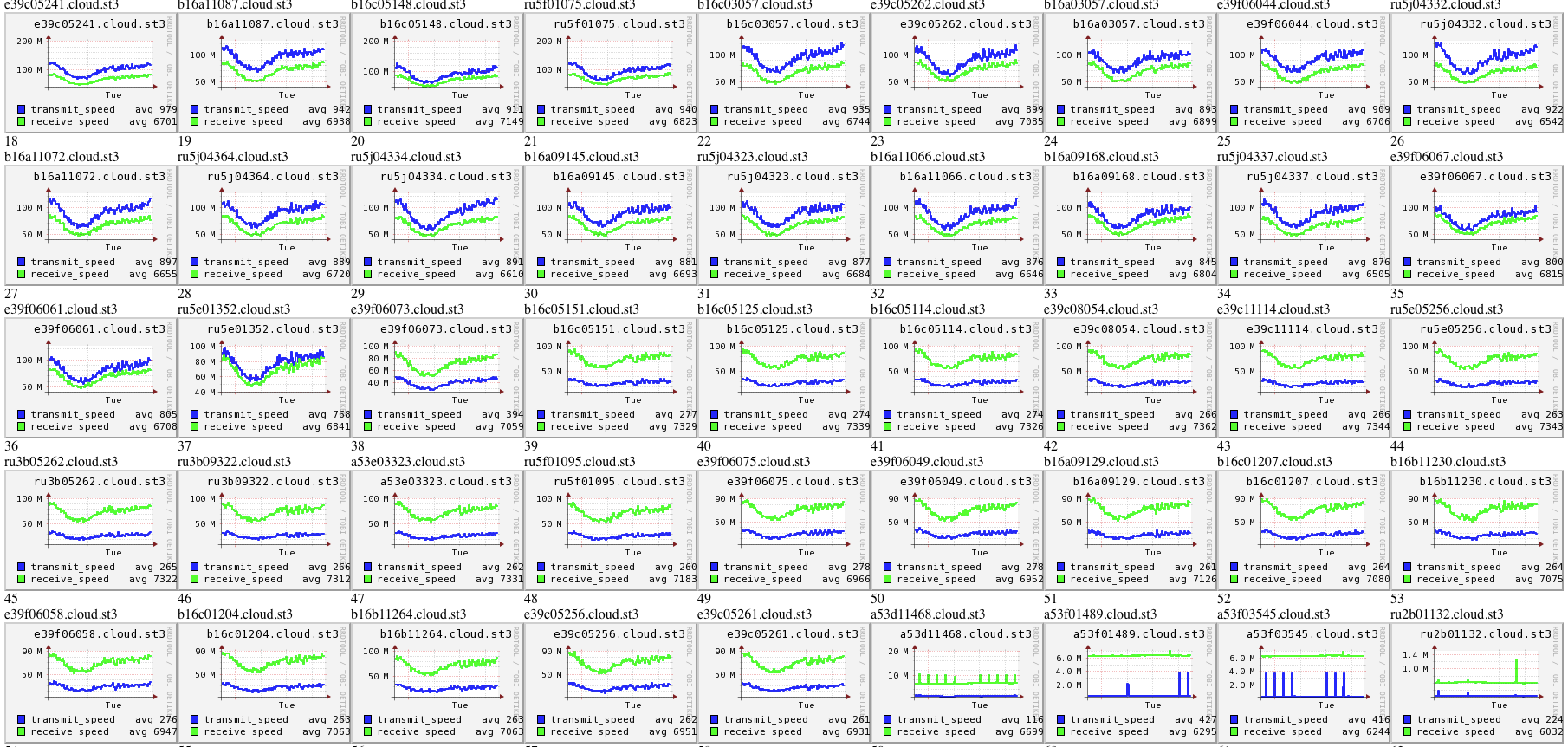
1.2 异常在时序上的抽象
- 异常值(Outlier):给定输入时间序列x,异常值是时间戳值对$(t,x_t)$,其中观测值$x_t$与该时间序列的期望值$(E(x_t))$不同。
- 断层(Change Point、Breakout):时序系统中某一时刻的值比前一时刻的值陡增或者陡降很多。
- 异常时间序列(Anomalous Time Series):给定一组时间序列$X={x_i}$,异常时间序列$x_i \in X$是在$X$上与大多数时间序列值不一致的部分。(这部分没有讲明白)
另外时间序列一般具有如下比较明显的特征:
- 趋势性:数据呈现某种持续向上或向下的趋势或者规律
- 季节性:数据呈现季节性,数据按照一定的规则进行往复出现
- 随机性:一些采集过程中的噪声或一些不规则的波动
2 时序建模
2.1 工业级算法设计思路
- 减小数据维度。通常时序数据是多维的,不仅仅是响应时间这一个维度。然而随着维度的增长,多时间序列异常异常检测的计算时间会快速增加。一般解决方法是做一些相关性分析,去除一些无关的维度。
- 使用简单的线性判别。往往越复杂的模型意味着很难更泛化地拟合真实的数据,因此我们提倡在算法的设计上,选择较为简单的线性方法进行粗略的异常判别,后续再使用更精确的算法对子区间进行判别。
- 尽量设计在线的算法。目前大多数异常检测方法均为静态方法,即对历史中特定段落的时间序列进行分析并得出结果。【再次中枪】然而在许多场景中时间序列是不断增长的,因此实时获得的时间序列中的异常同样迫切。
- 并行思想改善性能。这个思想哪里都可以用到。
- 时间和效果的trade-off。对于某些不需要高精度检测,但是实时性较强的环境,可以通过调整参数来达到相应的需求。
2.2 时序预测模型概况
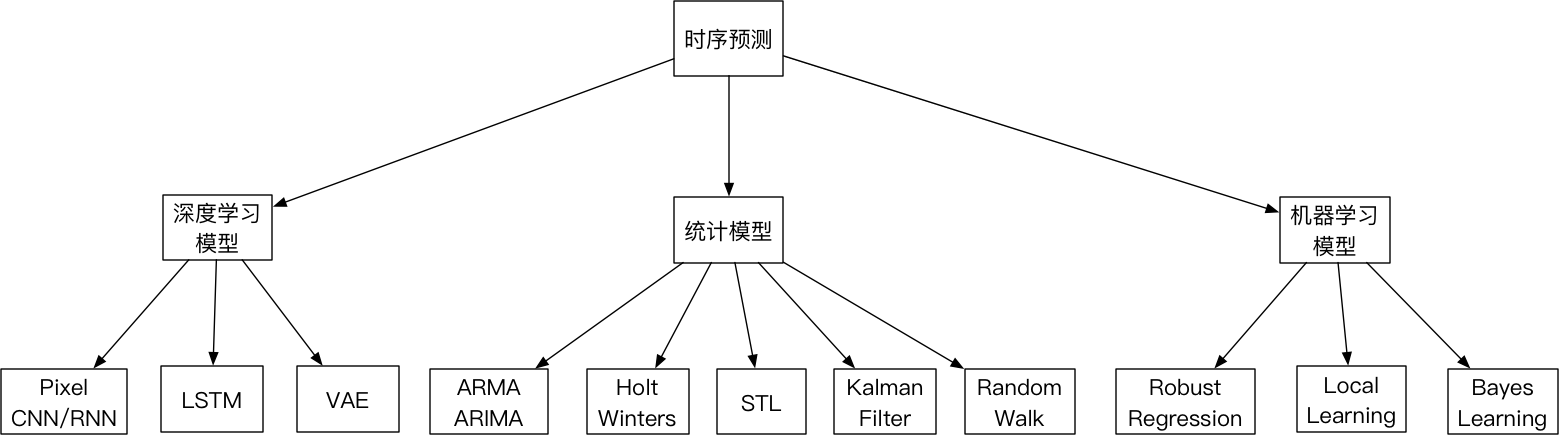
- 统计模型预测:其中自回归和移动平均模型,主要代表算法是ARMA系列;使用二阶或三阶指数平滑算法,主要代表算法是Holt Winters;对于趋势和周期序列,主要利用序列分解策略,主要代表算法是STL;同时也有利用卡尔曼滤波和随机游走算法进行时序的预测;
- 机器学习模型预测:消除时序中的噪点,利用鲁棒性回归和相应的随机过程(泊松过程、高斯过程等)配合使用Robust Regression;局部学习算法Local Learning;还有针对历史数据进行建模,利用贝叶斯算法进行时序预测;
- 深度学习模型预测:利用递归神经网络RNN,以及LSTM模型,进行时序预测;同时还有利用VAE(Variance Auto Encoder)算法将时序数据利用编码器的方式去噪声,并利用网络的强大拟合能力对其中数据缺失等问题得以解决;改进WaveNet模型使用CNN的形式去模拟部分RNN的策略较好的利用曲线的局部特征进行预测;
时间序列预测法用于短期、中期和长期预测。时间序列的本质特性是承认动态数据之间的相关性或依赖关系,这种相关性表征了系统的“动态”或“记忆”。如果这种相关性可用数学模型描述,则可有系统的过去及现在的取值预测其未来取值。
通过分析指标历史数据,判断未来一段时间指标趋势及预测值,常见有 Holt-Winters、时序数据分解(STL)、ARMA 系列算法。该算法技术可用于异常检测、容量预测、容量规划等场景。
3 时序异常检测算法
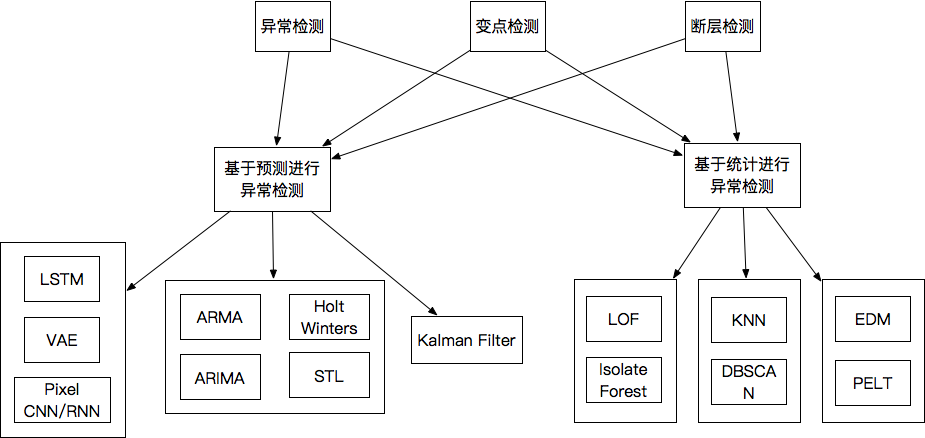
3.1 基于预测的异常检测
针对单条时序数据,可以利用时序建模方法预测,根据预测出来的时序曲线和历史数据求出时序的残差,对残差序列建模,利用k-Sigma或者分位数等方法进行异常检测。
直接进行时序建模之前要进行数据平滑、阈值检测等工作。
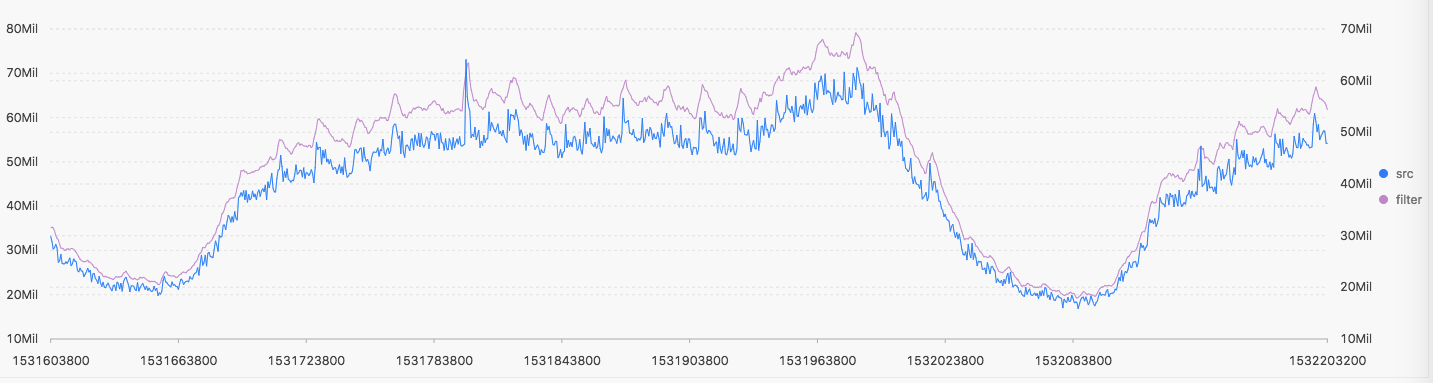
数据平滑:以网络流量曲线为例,该曲线局部都抖的很厉害,若对原始数据建模,则会吸收很很大的噪音,影响模型的效果,可以先用平滑函数对数据进行平滑处理。下图中,蓝色曲线是原始的网络流量数据,紫色是经过长度为5的矩形窗口平滑之后的结果。
阈值检测:为了避免单点抖动产生的误报,需要将求取累积的窗口均值进行阈值判别。具体的累积就是通过窗口进行操作:$(x_t+x_{t-1}+…+x_{t-w+1})/w$ 。
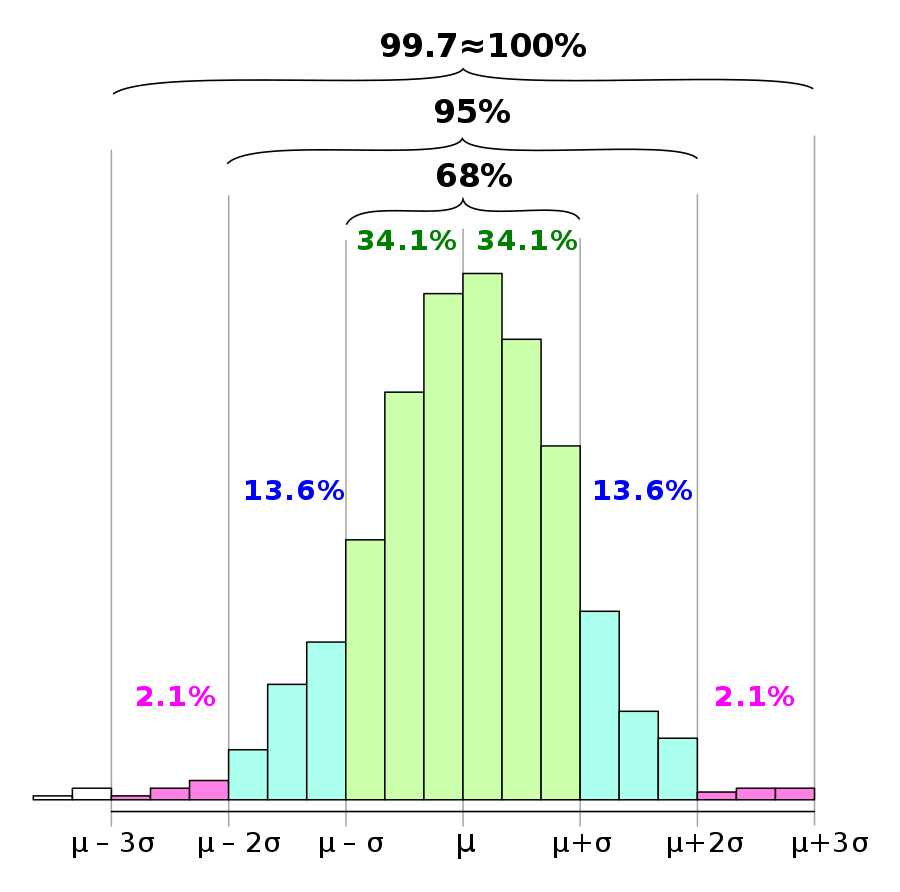
k-Sigma异常检测:假设数据集由一个正太分布产生,该分布可以用 $N(\mu,\sigma)$ 表示,其中$\mu$是序列的均值,$\sigma$是序列的标准差,数据落在$(\mu-3\sigma, \mu+3\sigma)$之外的概率仅有0.27%,落在$(\mu-4\sigma, \mu+4\sigma)$之外的区域的概率仅有0.01%,可以根据对业务的理解和时序曲线,找到合适的k值用来作为不同级别的异常报警。
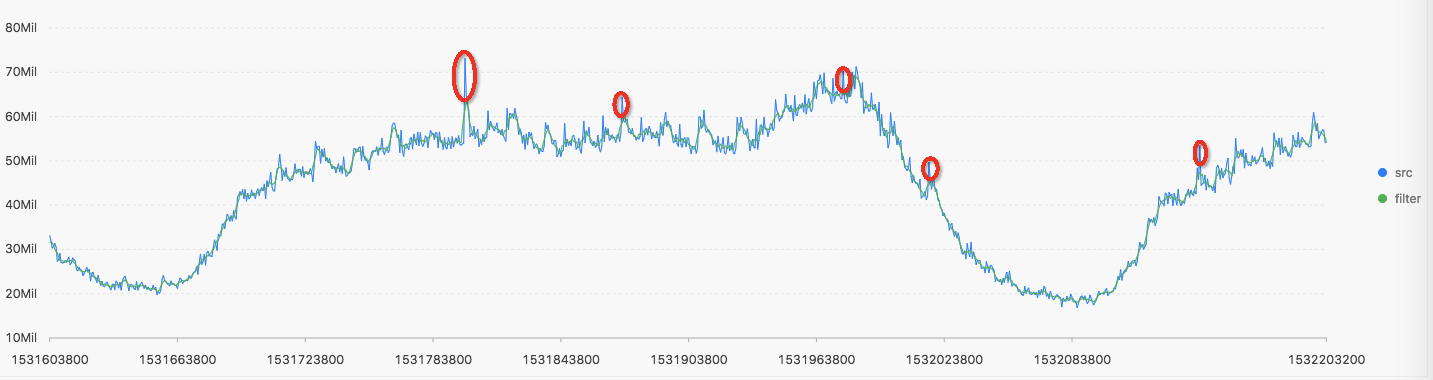
最后异常检测可以用下图来表示,其中绿色和蓝色曲线分别表示预测值和实际值。残差超过阈值的在途中用红色圆圈标记出来,即异常。
3.2 基于统计的异常检测
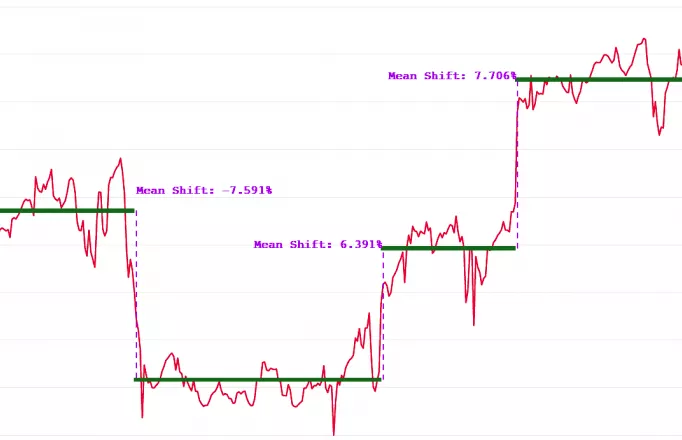
变点:给定时序数据,$z_1, z_2,…,z_n$,如果$\exists \tau$,使得$z_1, z_2, …, z_{\tau}$在某统计特性上区别于$z_{\tau+1}, z_{\tau+2}, …, z_n$,则$\tau$就是我们需要寻找的Change Ponit,数学看不懂看图:
常用的方法:
峰值分位数检测
将原始时序数据$x(t)$经过平滑后,求序列的一阶差分序列$x_{diff}(t)$,利用如下方法寻找异常值:
- 使用k-Sigma方法找到时序中的异常点
- 使用Quantile方法找到时序中的峰值点
均值漂移检测
给定检测窗口长度$w$,通过下式可以计算$t \in {2w, N}$之前每个点的均值漂移值。 $$ r(t)=\frac{x_t+x_{t−1}+…+x_{t−w+1}}{x_{t-w}+x_{t−w−1}+…+x_{t−2w+1}} $$ 根据检测出来$r(t)$值,利用k-Sigma异常检测方法,可以较好的得到时序中的断层点信息。
升级算法:EDM、PELT(后面可以了解一下)
4 实践
4.1 一个简单的例子
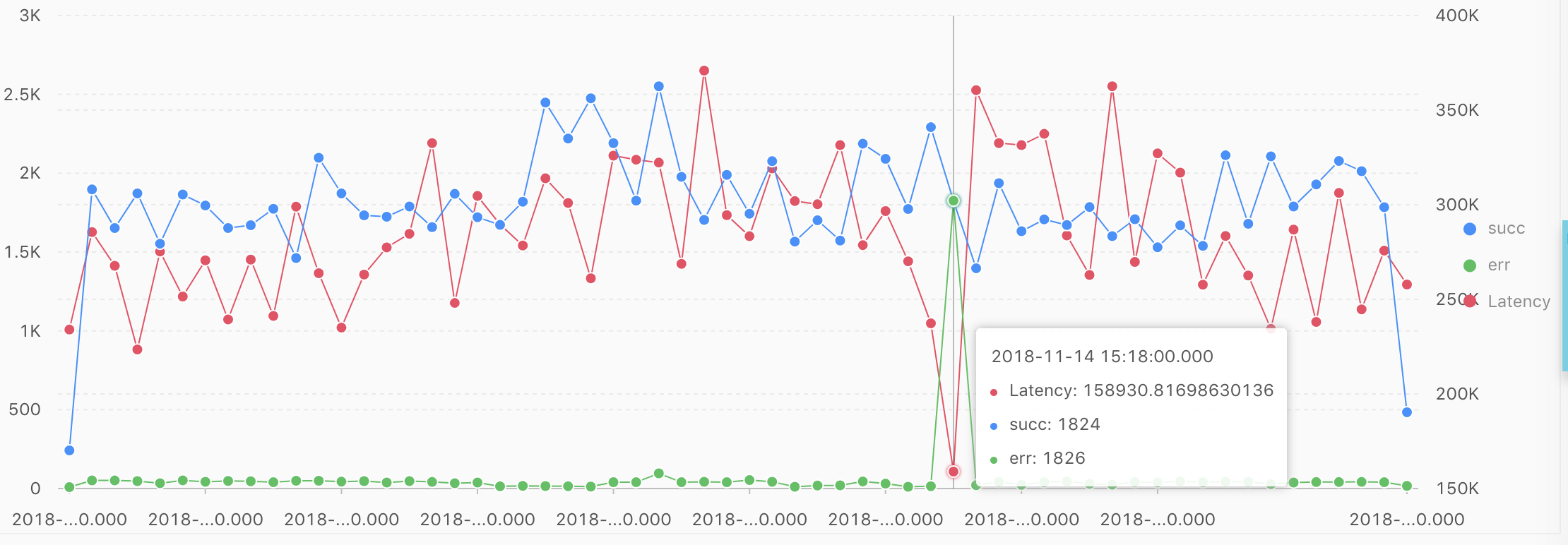
上图中的蓝色折线表示:每分钟平均请求成功的量;绿色折线表示:每分钟平均请求失败的量;红色的折线表示:每分钟平均请求的延迟。通过上图中的曲线可知,针对succ或这err这两个指标进行判断,却不能得到很好的判断,因此,将上述指标综合考虑一下,得到一个异常占比指标。
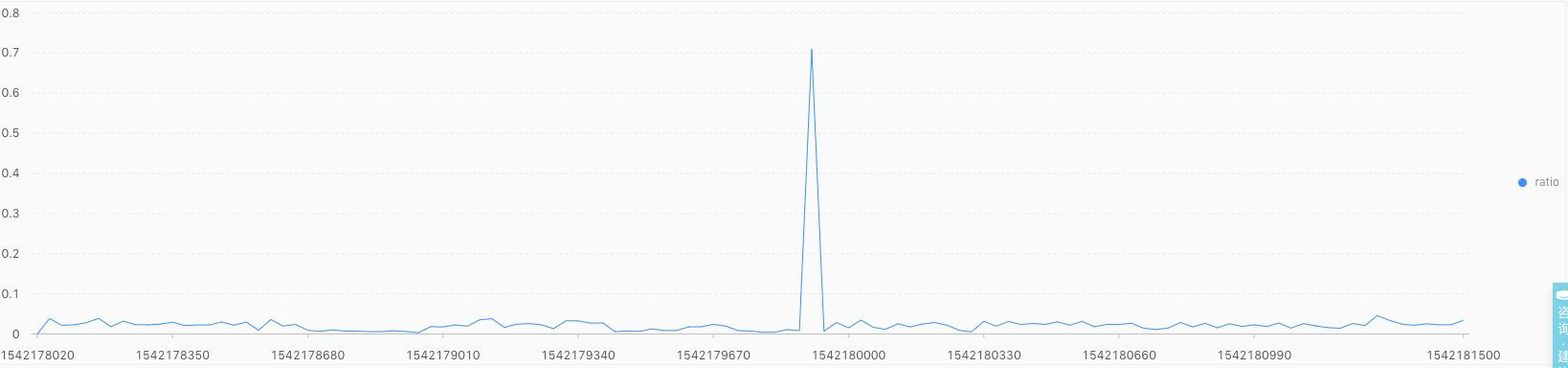
上图中表示每分钟$\frac{err}{succ + err}$的统计结果图,可以真实上述曲线进行时序建模,自动发现异常。具体的操作如下:
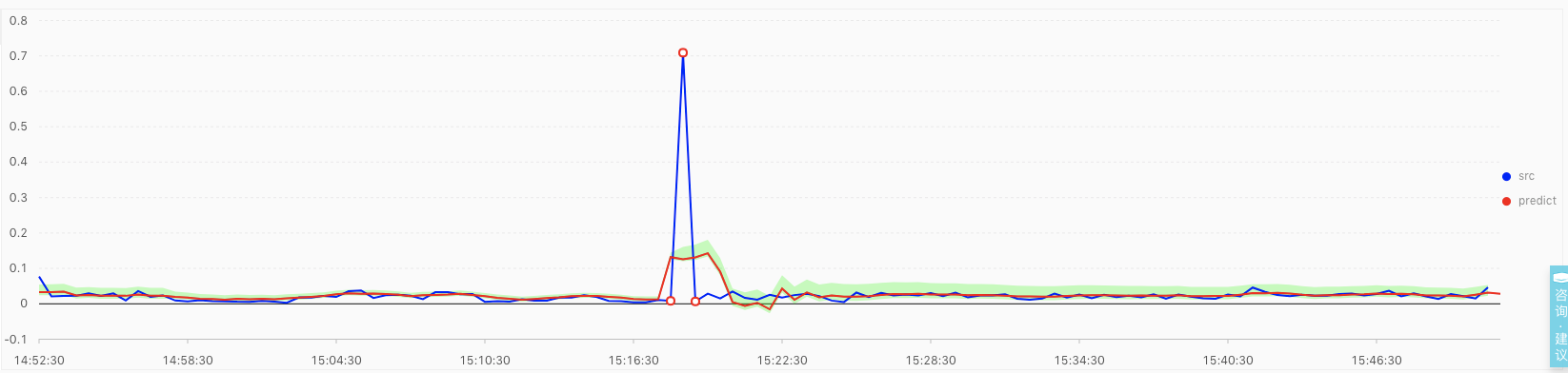
上图表示使用ts_predict_arma函数,对时序ratio 曲线建立时序统计模型 arma(p=5,q=1) ,并利用SLS(日志服务)中内置的异常检测策略,得到的检测结果。其中蓝色线表示实际的 ratio 时序状态,红色曲线表示针对历史数据学习得到的有效的预测曲线,浅绿色的区域表示有效的预测置信区间,红色的空心点表示发生异常的时间点。
4.2 一个抖动较大的例子
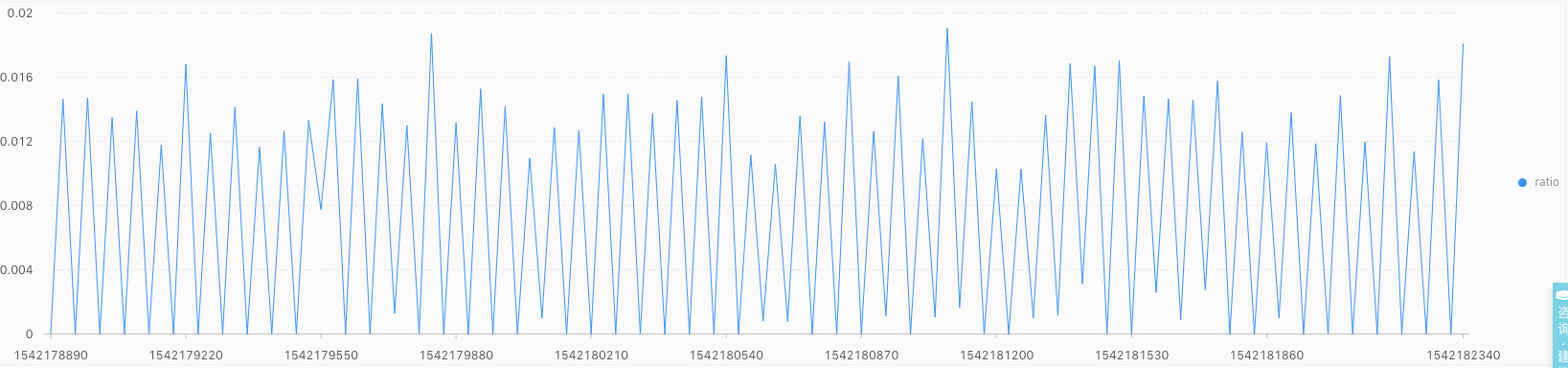
上图中 $\frac{err}{err + succ}$ 的抖动较为异常,分析下日志,大部分是因为请求时产生了400或者401的错误(除去请求的参数不对、或者是权限异常、或是心跳部分异常)。
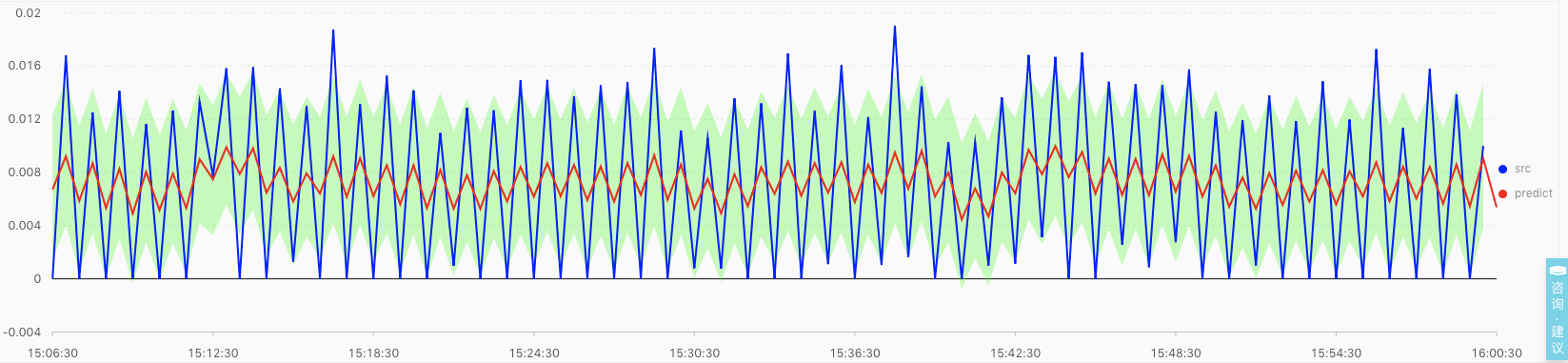
至于为什么有一些点超出了置信区间但是没有被视为异常的原因,是因为前面在时序建模的时候就提到了第一步是对原始数据做平滑操作的处理,能避免一些抖动带来的误判。最后数据平滑处理完的曲线和红色的predict曲线差不多,都在置信区间中所以没有异常。
4.3 Dashboard展示
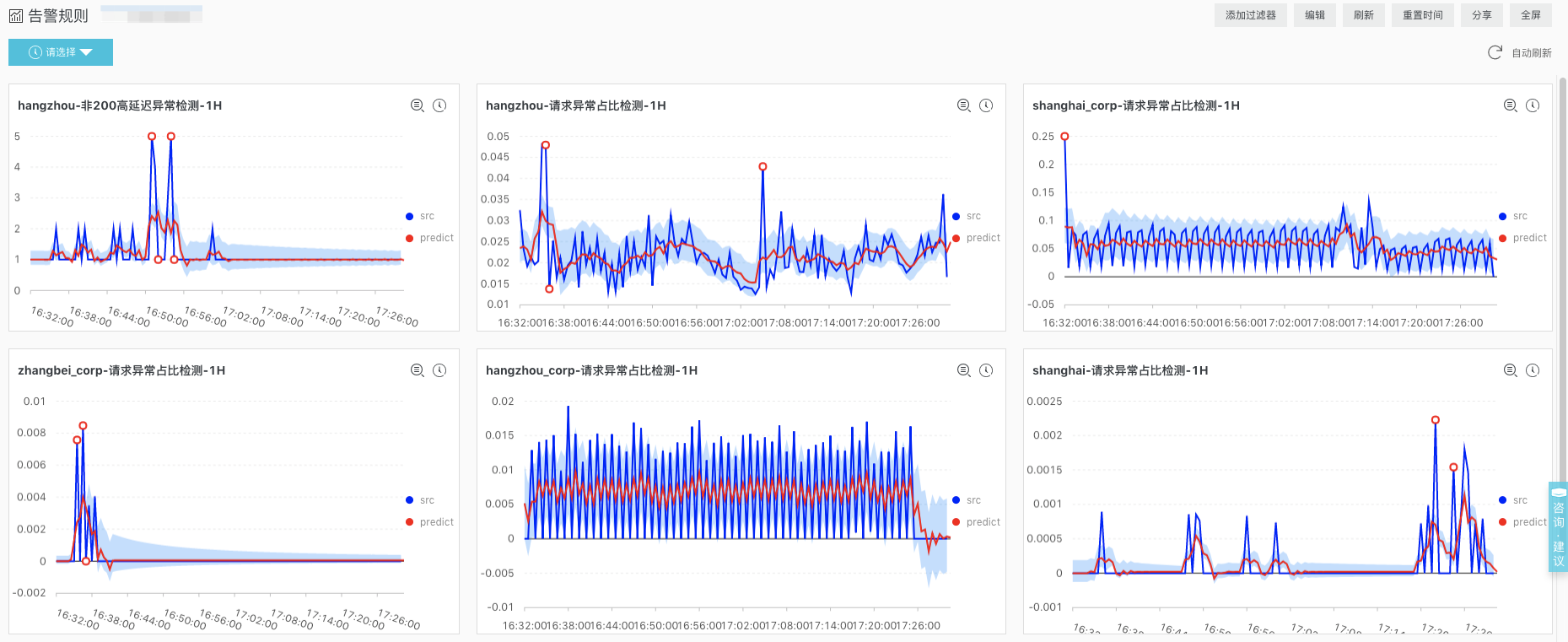
参考
https://developer.aliyun.com/article/658497 (时序建模 by 阿里云)
https://developer.aliyun.com/article/669164 (时序异常检测建模 by 阿里云)
https://developer.aliyun.com/article/670718 (时序异常检测案例 by 阿里云)